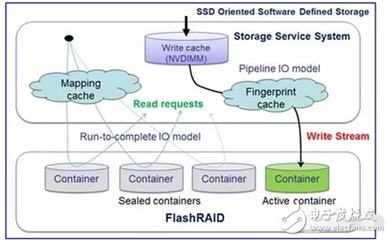
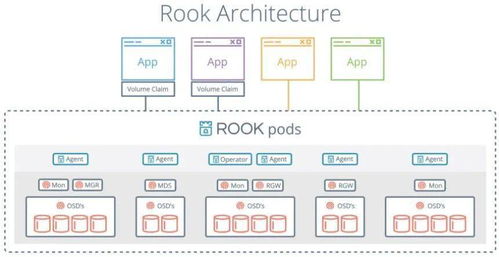
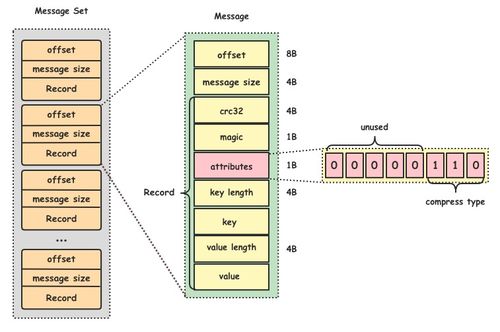
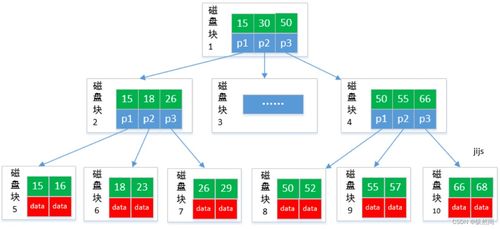
數(shù)據(jù)倉(cāng)庫(kù)、數(shù)據(jù)湖與湖倉(cāng)一體 核心區(qū)別與應(yīng)用場(chǎng)景
隨著大數(shù)據(jù)技術(shù)的發(fā)展,數(shù)據(jù)倉(cāng)庫(kù)、數(shù)據(jù)湖和湖倉(cāng)一體已成為企業(yè)數(shù)據(jù)處理和存儲(chǔ)的核心架構(gòu)。盡管它們都旨在管理海量數(shù)據(jù),但其設(shè)計(jì)理念、適用場(chǎng)景和技術(shù)特點(diǎn)存在顯著差異。
1. 數(shù)據(jù)倉(cāng)庫(kù)(Data Warehouse)
數(shù)據(jù)倉(cāng)庫(kù)是一種面向主題的、集成的、相對(duì)穩(wěn)定的數(shù)據(jù)存儲(chǔ)系統(tǒng),主要用于支持企業(yè)決策分析。它通常采用預(yù)定義的模式(Schema-on-Write),在數(shù)據(jù)寫(xiě)入前進(jìn)行清洗、轉(zhuǎn)換和結(jié)構(gòu)化處理。數(shù)據(jù)倉(cāng)庫(kù)擅長(zhǎng)處理結(jié)構(gòu)化數(shù)據(jù),并通過(guò)SQL查詢(xún)提供高性能的分析能力,適用于BI報(bào)表、OLAP等場(chǎng)景。它對(duì)半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)的支持有限,且數(shù)據(jù)導(dǎo)入流程較為復(fù)雜。
2. 數(shù)據(jù)湖(Data Lake)
數(shù)據(jù)湖是一個(gè)集中式存儲(chǔ)庫(kù),允許以原始格式存儲(chǔ)任意規(guī)模的結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。它采用后定義模式(Schema-on-Read),在數(shù)據(jù)讀取時(shí)再進(jìn)行處理和轉(zhuǎn)換。數(shù)據(jù)湖的優(yōu)勢(shì)在于靈活性高、成本較低,能夠容納多樣化的數(shù)據(jù)源(如日志、圖像、視頻等),并支持?jǐn)?shù)據(jù)探索和機(jī)器學(xué)習(xí)應(yīng)用。但其缺點(diǎn)包括數(shù)據(jù)質(zhì)量管理挑戰(zhàn)大,以及缺乏強(qiáng)一致性的治理機(jī)制。
3. 湖倉(cāng)一體(Lakehouse)
湖倉(cāng)一體是近年來(lái)興起的新型架構(gòu),旨在結(jié)合數(shù)據(jù)湖的靈活性和數(shù)據(jù)倉(cāng)庫(kù)的管理性能。它基于開(kāi)放數(shù)據(jù)格式(如Apache Parquet)構(gòu)建,在數(shù)據(jù)湖的基礎(chǔ)上添加了事務(wù)支持、數(shù)據(jù)版本管理和優(yōu)化查詢(xún)功能。湖倉(cāng)一體支持ACID事務(wù)、統(tǒng)一的元數(shù)據(jù)管理,并能直接運(yùn)行高效的BI和AI工作負(fù)載,解決了數(shù)據(jù)湖在數(shù)據(jù)質(zhì)量和一致性方面的不足,同時(shí)降低了數(shù)據(jù)倉(cāng)庫(kù)的復(fù)雜度和成本。
數(shù)據(jù)倉(cāng)庫(kù)適用于需要高度結(jié)構(gòu)化、穩(wěn)定分析的場(chǎng)景;數(shù)據(jù)湖適合存儲(chǔ)原始數(shù)據(jù)并支持靈活的數(shù)據(jù)探索;而湖倉(cāng)一體則致力于打破兩者界限,提供一體化的數(shù)據(jù)處理體驗(yàn)。企業(yè)在選擇架構(gòu)時(shí),應(yīng)結(jié)合自身的數(shù)據(jù)多樣性、實(shí)時(shí)性需求以及治理能力,做出合理決策。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.qobfjprovide.xyz/product/4.html
更新時(shí)間:2026-06-19 13:20:53